When I finished the post about my exploration of the algorithm to map from a distance to Hilbert coordinates and back, one of the things that still bothered me was that I had not yet implemented some of the optimizations that I could see were possible. For example, the unnecessary creation of additional HilbertCurveSegment class instances and the mapping through a set of basis vectors for what amounted to a simple bit rotation.
So, this afternoon I sat down and created an updated version (which I’ve added to the HilbertCurveExample repository) that implements these ideas. I haven’t bothered to benchmark it against the original but I’m sure it is a considerable improvement if only in terms of its memory footprint.
I had an additional motivation to finish this update. Midway through my work to get to the root of this algorithm, I ran a search (in a moment of frustration) that surfaced a stackoverflow posting whose answer offered what purported to be an actual implementation of the algorithm that I was looking for. Rather than read and implement it (like most normal people might), I simply scanned the code briefly to get a sense of the size and then set aside a link to it. Just seeing that an implementation was available in the event that I truly got stuck gave me enough motivation to press forward.
All the same, I wanted to have a look at this code and the paper associated with it – but not until I’d finished my work. I considered it a challenge to see how close my final solution would be (I still haven’t read it yet but I plan to do so once I finish this post).
The implementation that I completed today discards the HilbertCurveSegment class (which I had implemented in order to help frame the concept that a distance expressed an address related to the vertices of a set of nested N-cubes) and instead computed coordinate vectors, reflections, and basis vector transformations directly. I also discarded the idea of basis vectors since the only key principal that I needed to preserve was the rotation of the basis, which could be implemented more efficiently as a bit rotation. Finally, I attempted to express the concept of bit vector (and its relationship to an ordered sequence of vertices) more forcefully by providing certain variables a suffix of bitVector or vertexRank.
With all of these changes folded in, the final implementation reduces to a little more than 200 lines of code (with comments).
When I was younger, I got my hands on a copy of The Fractal Nature of Geometry by Benoit Mandelbrot. To my young mind, this revealed a fascinating new world of math with algorithms that promised to shape mountains and trees and, best of all, seemed to suggest a hidden landscape of complexity and seeming irregularity that lurked just underneath the simple and familiar mathematics that I knew.
Still etched in my mind, long after reading it, were images and names like the Sierpinski triangle, Peano curves, Hilbert curves, Julia sets, etc. As I grew older, my interests fanned out and the demands of daily life left me less time and energy to spend on these interests. So, while these things certainly still intrigued me, they came to mind less and less.
So I was pleasantly surprised a couple of months ago when my team began discussing the possibility of storing geospatial data in Microsoft’s Cosmos database and I read through the documentation to find that the implementation encoded geospatial coordinates as a Hilbert curve distance so that this distance could be used to create a searchable index. The idea made perfect sense to me but at the time, I had no idea how to map a distance to a Hilbert curve (or vice versa). The concept was interesting but, once again, life stepped in and my focus was driven elsewhere.
In mid-January, though, as I was working through a test case and wanted to generate a set of randomly-distributed coordinates, I started thinking about how a single random number between zero and one might be used to generate each of the coordinate pairs that I wanted if I treated the number as a Hilbert distance. While I went on to address this test in a different way, I went home thinking about mapping a distance to coordinates.
Looking For Direction
So, early on, I visited the Hilbert curve Wikipedia page, which featured an image of a three-dimensional Hilbert curve, an image labelled “production rules”, and C language source code for an algorithm to map between a distance value and a pair of coordinates on a Hilbert curve (and back again). The algorithm would have been very helpful if all I wanted to do was to implement the mapping – I could just port the code and walk away – but, by now, I was eager to pull the lid off of the Hilbert curve and take a look at what “made it work”.
By now, the three dimensional Hilbert curve begged the question, “how do I map between a distance and three coordinates, or five, or more?” Further, I wondered what would a three-dimensional slice of an N-dimensional Hilbert curve even look like? Why did the second order (or second degree as I fell into the habit of calling it) of a two-dimensional Hilbert curve turn head “right” at the onset rather than “up” like its first order ancestor? Yes, the “production rules” image said that this was the case but my question wasn’t about “what” the curve did – I was interested in “why?”
The most valuable clue that I found on the entire page turned out to be the statement that “Hilbert curves in higher dimensions are an instance of a generalization of Gray codes…” (somehow the statement that ” there are several possible generalizations of Hilbert curves to higher dimensions” and the associated footnote link to the paper entitled On Multidimensional Curves With Hilbert Property escaped my notice) It took a bit of exploration on my part before the importance of this statement really sank in.
Happily, for me, none of my searches turned up anything more helpful than this regarding the fundamental algorithm and I was left with this set of questions steadily growing roots in the back of my mind. I say “happily” because there is much greater satisfaction (and understanding) to be gained for an answer that is hard won versus one that is simply handed to me faîtaccomplis.
Finding My Way
So, without further guidance, I began to pick apart the Hilbert curve on my own. It didn’t take long to apply the production rules and demonstrate that, yes, if you follow the rules given, you end up with a nice two-dimensional Hilbert curve of any arbitrary order you want. I hacked together a method in Java that (or maybe I was working from someone else’s code that I had stumbled across) that selected the second order curve to insert based on the last segment that the algorithm had generated and the next segment in the ancestor curve. The algorithm looked essentially like this:
Orientation2D[] expand2d(Orientation2D previous, Orientation2D next) {
Orientation2D[] StepUp = { Right, Up, Left };
Orientation2D[] StepRight = { Up, Right, Down };
Orientation2D[] StepDown = { Left, Down, Right };
Orientation2D[] StepLeft = { Down, Left, Up, };
if (previous == Up && next == Up)
return StepUp;
if (previous == Right && next == Up)
return StepUp;
if (previous == Up && next == Left)
return StepUp;
if (previous == Down && next == Down)
return StepDown;
if (previous == Down && next == Right)
return StepDown;
if (previous == Left && next == Down)
return StepDown;
if (previous == Right && next == Right)
return StepRight;
if (previous == Up && next == Right)
return StepRight;
if (previous == Right && next == Down)
return StepRight;
if (previous == Left && next == Left)
return StepLeft;
if (previous == Down && next == Left)
return StepLeft;
if (previous == Left && next == Up)
return StepLeft;
throw new RuntimeException();
}
It wasn’t pretty but it wasn’t intended to be – all I needed at this point was a generator for an arbitrary curve so that I could look more closely at the results and try to extract a pattern. The interpreter for the resulting output simply incremented X when it encountered a Right instruction, decremented X when it encountered a Left instruction, incremented Y when it encountered an Up instruction, and decremented Y when it encountered a Down instruction.
One of the first things that I noticed about the output was that the first order curve had three steps such that, if it began at (0, 0), it would end at (1,0) and that the net effect of the curve was to advance to the right by one (when looking exclusively at the start point and end point).
First-order Hilbert curve in two dimensions
Meanwhile, the second order curve had fifteen steps such that, if it began at (0, 0), it would end at (3, 0) and the third order curve had sixty-three steps such that, if it began at (0,0), it would end at (7, 0). The clear linkage between the degree, the extents of the curve in the 2d coordinate space, and the length of the curve wasn’t lost on me but I still didn’t quite get what I was looking at.
Second-order Hilbert curve in two dimensionsThird-order Hilbert curve in two dimensions
I took some time to attempt the same decomposition for the construction of a 3d Hilbert curve but it didn’t take long before I realized that this was going to take a lot of effort and that I probably wouldn’t get any closer. Instead, I change gear and looked closely at a second order 3d Hilbert curve so that I could decompose it into a set of Up, Down, Left, Right, Away, and Toward instructions. I then generated a first and second order Hilbert curve and looked at the results.
Interestingly, the resulting set of instructions and extents showed a similar pattern to the 2d curve. The first order curve in two dimensions starting at (0,0) traveled up to (0, 1), then right to (1, 1), then finally traveled down to (0, 1) so that it visited all four vertices of a unit square. The first order curve in three dimensions starting at (0, 0, 0) traveled away to (0, 0, 1), then up to (0, 1, 1), then toward to (0, 1, 0), then right to (1, 1, 0), then away to (1, 1, 1), then down to (1, 0, 1), and finally toward to (1, 0, 0) so that the net movement was, again, one step to the right but only after visiting all eight vertices of a unit cube.
It began to sink in that, at each order, the resulting 2d Hilbert curve visited every vertex of every unit square within whatever area it covered. Similarly, the 3d Hilbert curve visited every vertex of every unit cube of whatever volume it covered. Maybe this doesn’t really seem like headline stuff – after all, the Hilbert curve is categorized as a “space filling curve” so it seems pretty natural that this is exactly what it would do. The thing that changed here, however, was my perspective on the movements required to accomplish this.
Black And White (But Gray All Over)
I finally turned to look again at the first order curve again and I finally noticed what the coordinates were telling me. If I took the first order 2d curve and treated the coordinates as a binary number, the sequence was simply:
00
01
11
10
Meanwhile, if I took the first order 3d curve and treated its coordinates as a binary number, the sequence became:
000
001
011
010
110
111
101
100
If you’re at all familiar with Gray code, you will probably recognize this sequence (and if you’re not, the Gray code Wikipedia page can tell you all sorts of things about it). This observation is central to the mechanism behind the generation of a Hilbert curve because each transition from one vertex to another in a Hilbert curve in any dimension travels along an edge – never along a diagonal. Saying this another way: along a Hilbert curve, moving from one vertex to the next always involves changing the value of only one coordinate (e.g. X or Y may change but never X and Y). This is exactly what a Gray code achieves.
Gray codes have been used in software and hardware because they possess this property: the transition from any Gray code value to the next Gray code value involves a change to the value of a exactly one bit. This is valuable in communication and positioning because the hardware or software can easily test for a change to two or more bits between adjacent values and report an error (e.g. to report an error and halt the movement of a robotic arm because the positioning sensor has become dirty and, therefore, unreliable).
Another interesting property of a Gray code is that any permutation of a Gray code is also a Gray code. That is, if we label the bits of our Gray code A, B, and C, the sequence in ABC (000, 001, 011, 010, 110, 111, 101, 100) can be remapped to BCA as (000, 010, 110, 100, 101, 111, 011, 001) but this sequence remains a Gray code. Our fist sequence in ABC corresponds to a Hilbert curve that originates at (0, 0, 0) and terminates at (1, 0, 0) while our second corresponds to a Hilbert curve that originates at (0, 0, 0) and terminates at (0, 0, 1). In effect, we can act as though we have a set of basis vectors that A, B, and C to X, Y, and Z and we can use this to orient our first order Hilbert curve so that it progresses up, right, or away.
So the Wikipedia article on the Hilbert curve really sort of buries the headline with the assertion that “Hilbert curves in higher dimensions are an instance of a generalization of Gray codes…” because any first order Hilbert curve is nothing more than a Gray code.
Turning To Progress In A New Direction
So, this is an important milestone – we can use this to construct a first order Hilbert curve in any number of dimensions. Moreover, we can find the set of coordinates for any vertex on this first order Hilbert from a simple distance value by converting that distance value to its corresponding Gray code value. In many languages (e.g. C, C++, Java, C#, etc.) we accomplish this easily with the statement:
long grayCode = value ^ (value >> 1);
Thinking about the process of generating a Hilbert curve, then, it seems that we can generate our second order Hilbert curve by simply replacing a segment along its path with the set of segments whose beginning and end map to that segment’s beginning and end. To illustrate this idea, we can look at the 2d Hilbert curve
The first order Hilbert curve is generated from a two bit Gray code:
This curve moves from the left to the right but it does so by first moving up from (0, 0) to (0, 1). We can find the appropriate variation of the first order 2d curve by simply exchanging the order of our A and B bits (or rotating the bits in AB):
Another way to think about this (though not a particularly efficient way to calculate it) is to imagine that we have our simple set of bits that encode our Gray code values (e.g. AB) and that we have a matrix that maps these AB bits onto our X, Y coordinate values. The matrix:
gives us A, B as X, Y while the matrix:
gives us B, A as X, Y.
So, we can construct our progress from (0, 0) in the second order 2d Hilbert curve by changing the mapping of (A, B) to (X, Y) so that X=B and Y=A in the (0, 0) quadrant. Then observation shows that the next two sections of the second order Hilbert curve are simply repeats of the first order curve but at different starting points so, here the mapping is once again X=A and Y=B in the (0, 2) and (2, 2) quadrants.
Reflecting On The Results
Still, we’re not quite there yet because when we reach the final leg of the first order Hilbert curve ancestor, and descend from (1, 1) to (1, 0), we have two problems.
Our first problem is that this section of the curve starts at (3, 1) and ends at (3, 0) so it would require a version of our first order Hilbert curve that starts at (1, 1) and ends at (1, 0). But there is simply no permutation of our A and B bits that will start at 11 and end at 10.
Our second problem is that, in this section of the curve, our X coordinate value must decrease during its movement from (1, 1) to (1, 0) in order to reach two of the four remaining unit square vertices at (2, 1) and (2, 0). Once again, there is simply no permutation of our A and B bits that will accomplish this for us. So, what is going on here?
Well, if you’re geometrically-minded, you’ve probably intuited that there is a left-right mirror symmetry to the second order Hilbert curve in 2d (in fact, it turns out that symmetry is an essential feature of Hilbert curves of all dimensions and of all orders). Once we reach the midpoint along our Hilbert curve, we’re actually travelling backwards over a reflection of the original curve.
A particularly convoluted (but very precise) way of looking at this is to say that, starting at the midpoint of our Hilbert curve, we begin to compute points based on a decreasing distance along a left-right mirror image of the first half of our Hilbert curve. Here is the convoluted (but precise) part:
If we were simply travelling backwards, we would be retracing the same set of coordinates. Since we are, instead, traversing a left-right mirror image of the first half of the Hilbert curve, we move right when would would move left. As a result, we continue to move right until we reach X=3 and then we progress down. Now, from (3, 1) to (3, 0), we traverse the mirror image of our first order Hilbert curve from the first quadrant by moving from (1, 1), to (0, 1), to (0, 0), and finally to (1, 0).
Connecting The Dots
So, at this point, we have all of the elements required to construct an algorithm to compute a point along an arbitrary dimension, arbitrary order Hilbert curve and the trick is just putting them together. Moreover, we actually have everything we need to convert from a set of coordinates back to a distance value. The only thing that remains is to put them together to give us the result that we want.
As I’m sure you’d have already guessed by now, I’ve already created an implementation of the code to do this and I’ve posted it in my Github repository as HilbertCurveExample. It feels like there are probably a few loose ends to tie up so I may return with a follow-up post.
Wikipedia
In case you can’t tell, I rely heavily on Wikipedia as a fantastic (and, I believe, seriously undervalued) resource for a lot of my resource. I make it a point to donate and I would like to encourage anyone reading this to donate to Wikipedia too
Comparing the results of my Fibonacci calculator in Haskell to those in Erlang revealed a few things. First of all, there was a bug in my Haskell implementation! The corrected version is:
import Data.List (genericIndex)
import Data.Bits
import System.Environment (getArgs)
-- simple Haskell demo to compute an arbitrarily large Fibonacci number.
--
-- this program relies primarily on the principle that F(n+k) = F(n-1)*F(k)+F(n)*F(k+1)
-- from which we find that F(2n) = F(n-1)*F(n) + F(n)*F(n+1) = F(n-1)*F(n) + F(n)*(F(n) + F(n-1))
-- Using the second equation, it is a simple matter to sequentially construct F(2^n) for any value n.
-- With this tool in hand, F(N) may be computed for any N by simply breaking N down into its constituent
-- 2^n components (e.g. N = 14 = 8 + 4 + 2 = 2^3 + 2^2 + 2^1) and to then use these results to guide
-- construction of the value we want by summing each of the F(2^n) using the F(n+k) identities described above
-- given two Fibonacci pairs representing F(n-1),F(n) and F(k-1),F(k), compute F(n+k-1), F(n+k)
fibSum :: (Integer, Integer) -> (Integer, Integer) -> (Integer, Integer)
fibSum (fnminus1, fn) (fkminus1, fk) =
(fnminus1*fkminus1 + fn*fk, fnminus1*fk+fn*(fkminus1+fk))
-- given an integer (representing the ordinal of the Fibonacci pair to be retrieved working value and a Fibonacci pair accumulator value,
-- compute return the sum of all Fibonacci values corresponding to the bits in N. For example, given a value of ten for N in F(N) -
-- bit values: False (2^0 = 1), True (2^1 = 2), False (2^2 = 4), True (2^3 = 8) - compute the sum of F(2 + 8)
fibGenerator :: Integer -> (Integer, Integer) -> (Integer, Integer) -> (Integer, Integer)
fibGenerator (n) tuple accumulator | (n == 0) = accumulator
| ((n .&. 1) == 1) = fibGenerator (shiftR n 1) (fibSum tuple tuple) (fibSum tuple accumulator)
| ((n .&. 1) == 0) = fibGenerator (shiftR n 1) (fibSum tuple tuple) accumulator
-- given a positive integer value N, compute and return Fib(N)
fib :: Integer -> Integer
fib (n) | n 0 = snd ( fibGenerator (n - 1) (0, 1) (0, 1))
-- main :: reads our argument and computes then displays corresponding Fibonacci number
main = do
args
Second of all, there was a significant difference in the performance of the two implementations. Since one was an almost direct port of the other, it was unlikely that the cause was in the code so it must be something inherent in the languages.
Haskell uses something called “non-strict” evaluation, meaning essentially that results of expressions are evaluated when they are needed and expressions whose results are never needed are never evaluated. In contrast, Erlang uses strict evaluation, meaning that each expression – whether its result is used or not – is computed in its entirety and the value stored. Of course non-strict evaluation can make certain types of operations more efficient but this is unlikely to make a big difference in the actual performance of the two implementations because the computation of Fibonacci numbers is largely a cpu-bound operation with few, if any, steps that can be skipped.
How big a difference is there between the two? Well, on my test virtual machine, the Erlang implementation computes in about 3.5 seconds (and another six seconds to display it) while the Haskell implementation computes and displays almost instantaneously. Taking it one order of magnitude further: the Erlang implementation computes in eight minutes while the Haskell implementation computes the same value and writes it to /dev/null in only two seconds.
Obviously, the difference between the two has to do with optimizations in the Haskell Integer library that are not present in the Erlang Integer library. There is also the possibility that the fact that Haskell is compiled and Erlang runs in its own virtual machine but I doubt this makes much of a difference. It’s fair to point out that Erlang has a principally business computing background while Haskell appears to me to have lived a long life in academic circles before entering the commercial world. It wouldn’t be the least bit surprising to find that the Haskell Integer library has received a little more attention.
But something interesting begins to emerge as larger and larger values are tried. Once it gets started, Erlang displays results at a very steady (and very swift) pace – pretty much what you would expect. Haskell, on the other hand, begins to display results in bursts of digits with larger numbers. For example, begins displaying in about 10 seconds and seems to pause every three seconds or so, sometimes for a barely noticeable fraction of a second and sometimes for ten or twenty seconds.
While it’s possible that this has to do with memory management in Haskell, I don’t believe it is. After all, the resulting number has only about 20 million digits while the virtual machine has 2 GB allocated. There isn’t really that much memory to manage.
Looking closely at the cpu profile makes the memory management interpretation seem even less likely. A single processor core ascends to 100% as soon as the program is launched. After about ten seconds, this core drops to about 20% while a few other cores also rise to 30%. This roughly coincides with the time that the program begins to display its results. After a relatively quiet period of five seconds, the original core rises once again to 100% (as all other cores idle down) and remains there for about ten seconds – during most of which time the display halts. Finally, this core drops once again to about 20% and the output resumes. For the rest of the run time, the load is largely distributed across all four cores allocated to my test virtual machine.
Clearly, the program is still hard at work as it displays the result but the question is: what is it doing? As I suggested in my last post, I suspect that it is still computing the result. All the evidence so far would seem to support this idea – but there is a catch:
To display the resulting Fibonacci number, the program must first convert it to a string in base 10. The way this is typically done is through successive integer division: divide the number by 10 which yields a remainder between zero and nine representing the least significant digit and a quotient representing all remaining digits. This approach can be successively applied to generate the digits one at a time starting with the least significant and ending with the most significant.
But if Haskell used this algorithm, it’s non-strict evaluation would be neutralized and it would have to perform every single calculation before it could display even the first digit. We would expect to see the exact behavior that we see from Erlang – a long delay and then a rapid stream of digits whose speed was paced only by the write speed of the video card. To get to the bottom of this puzzle, we have to look at Haskell’s algorithm to convert an Integer into a base 10 string. The function that does this is appropriately named integerToString and begins on line 479 of Show.lhs. This algorithm takes a completely different approach from the one described above and delivers two improvements: it is more efficient and it works better with Haskell’s non-strict evaluation.
The algorithm Haskell uses employs a “divide and conquer” strategy to reduce the original Integer into a List of Integer values by first repeatedly squaring (for the 64-bit version) until it finds the largest value that is less than the number to be converted. It then divides the number by this result to yield a List of two Integer values: the quotient and the remainder. This process is repeated until it has a List of Integers, each of which is less than – effectively representing the original number in base . These resulting Integer values are successively converted to base 10 strings starting with the first and proceeding through to the last.
So, how is this faster? Well, first it helps to think of an Integer value as a list of 64-bit integers – essentially digits in base . Each time such a number is divided, the algorithm must divide every digit. The traditional algorithm divides the entire number over and over again by 10, which reduces it by one order of magnitude each time. The highest order digit need only be divided about 18 or 19 times but the next to the highest digit is divided between 36 and 38 times (really, a little more than this, but let’s not split hairs). As we expand the series, we find that the sum of operations is roughly where n is the number of 64-big “digits”. In computer science terms, I believe this equates to time.
The Haskell algorithm involves first the repeated squaring to find the greatest power of that is less than the number to be reduced. The number of operations for this step grows relative to the number of 64-bit digits at a rate of roughly . The next step is the repeated division to reduce the number into a list of base digits. The number of operations for this phase grows at a rate of . The final step is to divide each of the resulting “digits” into base 10 digits – the number of operations for this step grows at a rate of roughly .
So, based on the above, the total operations for presenting a number with the Haskell algorithm is . This reduces to simply – showing that the Haskell algorithm runs in linear time. While its complexity may mean that it runs slower for smaller numbers (though I don’t think this is the case) it will rapidly outpace the performance of the typical algorithm, which runs in quadratic time, for any reasonably large Integer value.
To demonstrate this point for myself, I ported the Haskell algorithm to Erlang and gave it a try with my Fibonacci generator. Naturally, it had no impact on the rate at which the numbers were generated and it was hampered by the performance of the Integer library in Erlang but, nevertheless, it proved to be twice as fast at displaying the result of , coming in at only 3.6 seconds compared to 6.3 seconds for Erlang’s native conversion.
So this addresses how the Haskell algorithm is faster but what is it about this algorithm that makes it a better fit for non-strict evaluation? Well, as I pointed out earlier, the traditional base conversion algorithm would completely neutralize Haskell’s non-strict evaluation so it would be hard for it to be a worse fit. But let’s look at what steps Haskell must perform in order to find the first digit.
First, Haskell must perform all of the steps required to select a power of by which to reduce the number to be displayed. This requires approximately operations (where is the number of 64-bit integers in our number) – this step is irreducible. But we have sort of a shortcut here because we really only need to know the magnitude of the number we’re going to display at this point, not its precise value. This means that most of the time we need only resolve the most significant 64-bit digit (and to know the order of that digit) of it in order for this comparison to work.
Next, Haskell must break down the number by successively reducing it into a quotient and remainder. But here, we have a another shortcut – we are only concerned with the quotient, which means we can just park the remainder for now (in fact, I’m relatively certain that we don’t even need to calculate the low-order half of our Fibonacci number at this point). So, instead of completing the full series of operations to display the number, we only need to perform operations.
Finally, we only need to convert the top-most base digit into base 10 using the traditional base conversion algorithm, requiring only about 19 operations and then return the top-most digit.
Taken together, presentation of the first digit requires only operations. Not only is this less than the original it is less even than the operations in the improved algorithm. So, even if Haskell used the same Integer library as Erlang, it would be able to begin displaying the first digits of the number almost immediately. In fact, thanks to non-strict evaluation, Haskell probably wouldn’t even finish computing more than the first several 64-bit digits of the number before displaying the first base 10 digit. So the odd pauses and cpu profile during the display of Haskell’s results very likely do point to the fact that Haskell is still computing the result as it displays it.
Yesterday I suggested that the reason my old Haskell-based Fibonacci calculator program was so fast might be because Haskell was displaying the result before it was fully calculated. Now, the typical software development experience involves working with finite-sized integers (e.g. 16-bit, 32-bit, 64-bit, etc.) and floating point numbers. Almost without exception, the operations that a program performs against these types of values today are implemented completely on the processor so that they are essentially atomic – one moment all you have is two operands and the next you have the result. There is no in-between period where you have “part” of the result. As a result the idea that you might have one part of a numeric result and not have another may be somewhat counter-intuitive. But…
Most of the math that we perform, when we perform it by hand, is algorithmic. What I mean here is that we don’t simply multiply two large integers – we follow an algorithm that instructs us to multiply each of the digits and then add the results in a particular way. For example, suppose we multiply 521 by 482 to get 251122. Elementary school multiplication has us perform the following steps:
1) designate one number the multiplicand and the other the multiplier (I’ll choose 521 as the multiplicand and 482 as the multiplier)
2) choose the lowest order digit of the multiplier and note its magnitude (e.g. the power of ten corresponding to its position)
2) multiply each of the digits of the multiplicand by the power of ten corresponding to its place and by the multiplier digit you just selected, starting with the least significant digit of the multiplicand and working our way up, summing the results as we go and finally multiply the sum by the magnitude of the multiplier digit.
3) repeat step two for each of the remaining digits of the multiplier and their corresponding magnitudes.
4) finally, we sum these values to obtain our result:
The math that the processor performs on our behalf for finite integers uses the same algorithm to produce its result (only the computations are in base 2 instead of base 10). What I mean here is that while the processor does all of the work for us, even at the silicone level, the result is actually computed in stages. These stages might simply be cascades of gates but there is still a series of “steps” or “stages” involved in generating the number.
When a computer program performs arbitrary-precision math multiplication operations (aka BigInteger math), it uses the same algorithm, or one of a few more efficient alternatives, to compute the result. But what if we could get part of our result early? Perhaps we could take advantage of a few extra processor cores and start working with it.
Well, it turns out that we can, in most cases, get part of our result much earlier. All we have to do is change our order of operations. This typical grade-school version of the multiplication algorithm is devised for simplicity. While the way I’ve written it makes it look a bit more complex, the order of operations is roughly the same and I hope it makes it easier to understand the reordering. So let’s look at a different way of computing this result.
First we would like to get an idea of the magnitude of our result. Already we know that it has to be expressible in six digits since we’re multiplying two three digit numbers but we might like to know the most significant digit because that will get us a lot closer. That value is simply the highest order digit of the product of the two highest order digits plus any “carry” digits. In our case, 4*5=20 and, even after we factor in the carry from subsequent operations that we must add to our result, it is pretty easy to demonstrate that, since the least significant digit of 20 is zero, the addition of carry digits could never result in a change to our most significant digit: 2.
For the next digit, though, we’ll need the sum of any carry digits from lower order operations. Our next digit is the least significant digit from our first calculation (it’s worth pointing out that our previous calculation may have had only one digit, in which case we’d have skipped to this step) plus the most significant digit of the sum of our next lower order calculations plus any carry from lower order operations.
Since our second digit is non-zero, we need to consider carry so we have to perform the next operation:
Now we know that we don’t need to worry about carry from the next operation so we can finish computing the previous result:
Now there is still a chance that our next operation will yield a result that will affect our least significant digit of 1 but we can now reliably say that our next most significant digit will be 5. So now we’ll compute the next value.
Now there is no chance that adding this plus any carry could affect our 1000s digit so we can safely say that our next most significant digit is the 1 from our calculation above. So now our result so far is: 251000. All we have to do is finish our final calculation, which is simply:
Adding this to the result above, we get 122, which we can add to our result in progress to get 251122.
Now, yes, I’ve been fast and loose with the operations and I haven’t really provided a formal algorithm but I’m sure you can see the general framework. The more important point here is that I was able to work out the most significant digits early in the operation. While this isn’t particularly helpful when dealing with calculations involving six digit results, it can be crucial when working with arbitrary precision results involving hundreds of millions of digits. In these cases, knowing the most significant digits can enable you to start reporting the result before you’ve finished calculating it or simply to determine that it is outside the bounds of the problem set, etc.
There are two keys to taking advantage of this. The first is structuring calculations in a manner like the one above so that higher order computations required to determine the most significant “digit”(s) occur first. The second is structuring this evaluation so that these results are available to “callers” as soon as they are known. In a traditional language, this might involve some relatively exotic programming so this is where we go back to Haskell and functional languages in general.
Haskell performs computations using “non-strict” evaluation. This basically means that if you never request a result, it is never computed. Equally as importantly, when you do request a value, all of the calculations specific to computing it are performed at that moment. In a very real way, it’s as though when a Haskell program ran, it simply generated a set of instructions for computing the result needed and returned these to the caller. When the caller decided to report the result, he would read the recipe and performed the operations it contained to compute the result.
Since BigInteger math consists of working with numbers that are simply strings of digits in, say, base 4294967296, the same basic algorithm described above could be applied to yield the most significant “digits” early. These results could go directly to the next calculation or to a base 10 conversion so that they can be displayed in human-readable format. If Haskell’s base 10 conversion were built to work with higher order digits first then we might very well see the result that I first described – that the result was still being calculated as it was displayed.
In practice, Haskell may not perform this level of “pipelining” for arbitrary precision math operations and it is quite possible that BigInteger results must be computed fully before they become available for subsequent operations. My point here isn’t to say what Haskell does as much as it is to point out what is possible – particularly as it relates to taking advantage of more processor cores. It is possible that Haskell’s performance has somewhat more mundane roots. To this point, next time, I’ll take a look at the algorithm that I think is currently used by Haskell for base 10 conversion and how it fits in to this picture.
Before I get into the subject of this post, let’s address a little business. You may notice that my blog looks different today. First of all, the url is different – halstclair.com instead of halstclair.com/TechnicalDetails. The second, and, in my opinion, more important difference is that it is more responsive. Let’s just say that my previous host wasn’t getting the job done so I’ve done some major rearranging behind the scenes and what you’re seeing is the result.
Now, on to the subject at hand…
A few years ago, I thought I’d look around at functional languages to see what they had to offer. I’d seen a few articles pointing out that we were rapidly nearing the end of our ability to scale computing performance efficiently by increasing processor clock rates. Instead, we would be challenged over the coming years to make efficient use of increasing numbers of processor cores and that the secret to making this happen would be the kind of parallelization that was innate in functional languages. So it seemed like a good time to get acquainted with these languages.
At the time, Erlang and Haskell were fairly well established and languages like F# and Clojure (as well as others) were emerging. I settled on Haskell primarily because a few references suggested that it was among the oldest and the most purely functional language among the lot (I don’t really want to debate this particular point because I don’t have enough experience with the others to form my own opinion but this was the impression I got).
Soon after starting to work with Haskell I thought I’d try something a little beyond the typical “hello world” so I started experimenting with a simple program to calculate Fibonacci numbers – give it an index, say 10, and it would produce the corresponding Fibonacci number, say 55. Of course, the naive algorithm for computing Fibonacci numbers is just where and so it was easy enough to implement. Haskell has built-in support for arbitrary precision integer math so my first implementation could calculate essentially any Fibonacci number that I had the patience to wait for. The problem was that this algorithm was expensive so, as I experimented with computing higher and higher ordered Fibonacci numbers, it quickly came to be like watching paint dry.
That would have been the end of the story but…
Looking at the sequence one day, I noticed that was 144. Now that’s a pretty odd coincidence (since is also ) and while it was obvious that there was no such relationship for any other Fibonacci number, it made me curious so I started doodling with squares of Fibonacci numbers. It wasn’t long before I stumbled across the fact that . A little more mucking about revealed that this particular pattern () persisted for every pair Fibonacci numbers that I cared to try. A quick look at Wikipedia (see Fibonacci Number) revealed that this was just a special case of a well-known identity:
In relatively short order, I worked out the following useful variation: . This formula provided a way to rapidly calculate the series for and to compute the ‘sum’ of any combination of these values to generate any arbitrary Fibonacci number (i.e. ).
The source for the resulting program was:
import Data.List (genericIndex)
import System.Environment (getArgs)
-- this set of functions can be used to calculate an arbitrarily large Fibonacci number.
-- it relies ultimately on the principle that F(n+k) = F(n-1)*F(k)+F(n)*F(k+1)
-- from here we find that F(2n) = F(n-1)*F(n) + F(n)*F(n+1) = F(n-1)*F(N) + F(n)*(F(n) + F(n-1))
-- using the second equation, it is a simple matter to construct an infinite list of Fibonacci numbers, see fibPwr2Pairs, F(Xn) where Xn = 2^n
-- Then, to arrive at F(n) where n is an arbitrary positive integer, we decompose n into its constituent bits and find the Fibonacci number pairs
-- corresponding to each of the bit values (e.g. given n=5 we have bit 0 = True, bit 1 = False, bit 2 = True - we therefore find the pairs (0, 1) and
-- (2, 3)) Finally we use the first principle to transform these pairs inot the Fibonacci pair corresponding to the sum of the bit values.
growAPair :: (Integer, Integer) -> (Integer, Integer) -- given a Fibonacci pair (F(n-1), F(n)) yields the pair for 2*n i.e. (F(2*n-1), F(2*n))
growAPair (fnminus1, fn) = (fnminus1^2 + fn^2, fn * (2*fnminus1 + fn))
-- fibPwr2Pairs :: yields an infinite list of the Fibonacci pairs occuring at powers of two
-- (This works out well for us because Haskell uses lazy evaluation! Members of the list are only calculated as they are needed)
-- i.e. [F(2^0) = (1, 0), F(2^1) = (1, 1), F(2^2) = (2, 3), ... F(2^n) = (F(2^n), F(2^n - 1))]
fibPwr2Pairs :: [(Integer, Integer)]
fibPwr2Pairs = iterate growAPair (0,1)
-- binaryDecompose :: decomposes the supplied integer value into its constituent bits and returns this as a list of Bool values with the
-- least significant bit first in the list.
binaryDecompose :: Integer -> [Bool]
binaryDecompose n = map odd -- transforms the list of integers into boolean values indicating whether each original integer was odd
(takeWhile (/= 0) -- limits the list of integers to those whose value is non-zero - otherwise it would have an infinite number of trailing zeros
(iterate -- apply the following function to build an infinite list of n divided by increasing powers of two (starting with 2^0)
(\value -> quot value 2) -- lambda function that accepts a value and returns that value divided by 2 (as the first argument to 'iterate')
n)) -- the number to be decomposed (as the second argument to 'iterate')
-- fibSum :: this function takes an array of fibonacci pairs in the form (F(Xn-1), F(Xn)) and calculates the Fibonacci number for the sum of all Xn
-- i.e. for the array [FibPair F(1), FibPair F(2), FibPair F(8)] the result of fibSum would be FibPair F(1+2+8) = F(11)
-- this relies on the simple fact that F(n+k) = F(n-1)*F(k)+F(n)*F(k+1)
fibSum :: [(Integer, Integer)] -> (Integer, Integer)
fibSum ((a, b) : []) = (a, b)
fibSum ((fibOfAMinus1, fibOfA) : (fibOfBMinus1, fibOfB) : xs) = fibSum ((fibOfAMinus1 * fibOfBMinus1 + fibOfA*fibOfB, fibOfAMinus1 * fibOfB + fibOfA * (fibOfBMinus1 + fibOfB)) : xs)
-- tupleFilter :: this function is a simple filter function used by filteredFibPwr2Pairs to eliminate Fib pairs corresponding to bits whose value is zero
-- This may be unnecessary but I could not get the Lambda syntax to work out. In any event, it's probably a little clearer broken out like this.
tupleFilter :: (Bool, (Integer, Integer)) -> Bool
tupleFilter (bool, (a, b)) = bool
-- filteredFibPwr2Pairs :: this function accepts a value n and generates the set of Fibonacci pairs needed to calculate F(n)
-- this is where our infinite list of Fibonacci pairs joins our decomposed n to yield the Fibonacci pairs required to generate our result
filteredFibPwr2Pairs :: Integer -> [(Integer, Integer)]
filteredFibPwr2Pairs n = snd (unzip (filter tupleFilter (zip (binaryDecompose n) fibPwr2Pairs)))
-- fib :: calculate an arbitrary Fibonacci number
fib :: Integer -> Integer
fib n = snd (fibSum (filteredFibPwr2Pairs n))
strToInteger :: String -> Integer
strToInteger = read
-- main :: reads our first argument as the Fibonacci number to be calculated.
main = do
args
I’m not pretending that this was beautiful Haskell code – it was just one of my early efforts. But here is the interesting thing: when I ran this program for large values of n and routed the output to a file, Haskell used all of the RAM I allowed it to have (and multiple processor cores if I remember correctly). The processor load went to 100% as soon as I hit enter and stayed there as it began to produce output. Later, after perhaps 25% of the digits had been generated, the processor load would drop to perhaps 25% to 40% and remain there until all of the output had been produced.
I’m going out on a limb here but the way that I interpreted these results was that the application was displaying the result even as it was still working to compute it. Now this isn’t a particularly important behavior for most applications, since most applications don’t involve a lot of arbitrary precision math but, if my interpretation were right, it pointed to a deep kind of “laziness” that inherent in Haskell’s non-strict evaluation that I found very interesting.
To investigate this further, I rewrote this application in Erlang recently (and in Java, just for contrast) and compared the performance of these applications. Surprisingly, I found that my Haskell implementation was dramatically faster, producing the one millionth Fibonacci number in under a second while Erlang took nearly ten seconds (to be fair, I ran my Erlang version in the Erlang equivalent to Haskell’s ghci but the Haskell version produces near-instantaneous results ghci, too). To be certain that I was looking at real results, I rewrote the Haskell version so that the logic was nearly identical between the final Haskell and Erlang versions and still saw the same result.
Here is the source for the two resulting programs:
Erlang
-module(fib).
-export([fib/1, fibSum/2, fibGenerator/3]).
% fibSum -- this function takes two fibonacci pairs in the form (F(n - 1), F(n), F(k - 1), F(k)) and caculates
% the Fibonacci number for F(n+k). I.e. for the two pairs (F(1), F(2)), (F(3), F(4))
% the result of fibSum would be FibPair F(2+4) = F(6)
% this relies on application of the formula F(n+k) = F(n-1)*F(k)+F(n)*F(k+1)
fibSum({FibOfAMinus1, FibOfA}, {FibOfBMinus1, FibOfB}) ->
{FibOfAMinus1*FibOfBMinus1 + FibOfA*FibOfB, FibOfAMinus1*FibOfB + FibOfA*(FibOfBMinus1+FibOfB)}.
% given an array of booleans (representing the bits of N in F(N), LSB first), a Fibonacci pair working value and a Fibonacci pair accumulator value,
% compute return the sum of all Fibonacci values corresponding to the bits in N. For example, given a value of ten for N in F(N) -
% bit values: False (2^0 = 1), True (2^1 = 2), False (2^2 = 4), True (2^3 = 8) - compute the sum of F(2 + 8)
fibGenerator(0, _, Accumulator) -> Accumulator;
fibGenerator(N, FibPair, Accumulator) when (N band 1 =:= 1) ->
fibGenerator(N bsr 1, fibSum(FibPair, FibPair), fibSum(FibPair, Accumulator));
fibGenerator(N, FibPair, Accumulator) ->
fibGenerator(N bsr 1, fibSum(FibPair, FibPair), Accumulator).
% given a positive integer value N, compute the Fibonacci number Fib(N)
fib(N) when (N =:= 0) -> 0;
fib(N) when (N =:= 1) -> 1;
fib(N) when (N > 0) ->
{_,Result} = fibGenerator(N-1, {0,1}, {0,1}),
Result;
fib(_) -> ok.
Haskell
import Data.List (genericIndex)
import Data.Bits
import System.Environment (getArgs)
-- simple Haskell demo to compute an arbitrarily large Fibonacci number.
--
-- this program relies primarily on the principle that F(n+k) = F(n-1)*F(k)+F(n)*F(k+1)
-- from which we find that F(2n) = F(n-1)*F(n) + F(n)*F(n+1) = F(n-1)*F(n) + F(n)*(F(n) + F(n-1))
-- Using the second equation, it is a simple matter to sequentially construct F(2^n) for any value n.
-- With this tool in hand, F(N) may be computed for any N by simply breaking N down into its constituent
-- 2^n components (e.g. N = 14 = 8 + 4 + 2 = 2^3 + 2^2 + 2^1) and to then use these results to guide
-- construction of the value we want by summing each of the F(2^n) using the F(n+k) identities described above
-- given two Fibonacci pairs representing F(n-1),F(n) and F(k-1),F(k), compute F(n+k-1), F(n+k)
fibSum :: (Integer, Integer) -> (Integer, Integer) -> (Integer, Integer)
fibSum (fnminus1, fn) (fkminus1, fk) =
(fnminus1*fkminus1 + fn*fk, fnminus1*fk+fn*(fkminus1+fk))
-- given an integer (representing the ordinal of the Fibonacci pair to be retrieved working value and a Fibonacci pair accumulator value,
-- compute return the sum of all Fibonacci values corresponding to the bits in N. For example, given a value of ten for N in F(N) -
-- bit values: False (2^0 = 1), True (2^1 = 2), False (2^2 = 4), True (2^3 = 8) - compute the sum of F(2 + 8)
fibGenerator :: Integer -> (Integer, Integer) -> (Integer, Integer) -> (Integer, Integer)
fibGenerator (n) tuple accumulator | (n == 0) = accumulator
| ((n .&. 1) == 1) = fibGenerator (shiftR n 1) (fibSum tuple tuple) (fibSum tuple accumulator)
| ((n .&. 1) == 0) = fibGenerator (shiftR n 1) (fibSum tuple tuple) (fibSum tuple accumulator)
-- given a positive integer value N, compute and return Fib(N)
fib :: Integer -> Integer
fib (n) | n0 = snd ( fibGenerator (n - 1) (0, 1) (0, 1))
-- main :: reads our argument and computes then displays corresponding Fibonacci number
main = do
args
From a computing perspective, there is something deeply non-intuitive about displaying a result that we are still calculating but after mulling it over I think that this may not be quite so strange as it seems. Irrespective of whether this is what Haskell is actually doing, I’ll try tomorrow to address why I think this might actually be possible and that a language like Haskell might be the perfect environment to make it happen.
As I thought about last night’s post, I was bothered by how confusing it seemed and I finally decided that the reason is that I never directly addressed what was happening. Yes, I provided an expansion and mentioned the idea of partial function invocation but I never really generalized this idea. So today seems as good a time as any…
In Haskell, when we talk about partial function execution or “currying” we’re referring to the idea that a function with two or more parameters can receive some of it’s parameters now and others later. Take a look at the following function declaration (the declaration is the first line, the definition is the second line):
myFunc :: (Num a) => a -> a -> a
myFunc a b = a * b
What this function declaration tells us is that myFunc takes a parameter of type a and a second parameter of type a and returns a result of type a. But there is more going on here. Look at how we define the final returns: -> Why would we use this same symbol between the first and second parameters? The reason is that the definition is telling us something very deep about how Haskell approaches functions – what it’s really saying is that myFunc accepts a parameter of type a and returns a result that is a function. This resulting function accepts a parameter of type a and returns a result of type a.
Let’s rewrite the function declaration to perhaps make this point a bit more clear:
myFunc :: (Num a) => a -> (a -> a)
myFunc a b = a * b
we could “curry” or partially execute this function with the following expression:
(myFunc 7)
This expression yields a function that will accept any value and multiply it by 7 – all it needs is that second parameter. Now don’t be fooled into thinking this is a simple parlor trick and that all we’ve really done is put parentheses in an odd place. Haskell allows us to pass this “curried” function as a parameter to any function that accepts a function argument that is required to accept a Num and return a Num.
We can do the same thing with the built in * function:
((*) 7)
Placing the * operator in parentheses like this simply allows us to treat it like a ‘normal’ function with two following parameters. In our expression, we provide it with a value of 7 for the first of these two parameters. When we later use this function by providing it with a Num for its second parameter, it will return that value multiplied by 7.
Again, this isn’t just a shell game – this is how work gets done in Haskell. Consider the map function which takes a function and applies it to every member of a list to generate a new list. The function that it accepts as a parameter is required to consume one parameter and return one result. If we wanted to use map to multiply ever member of a list containing [1,2,3] by 7 then we could simply say:
map ((*) 7) [1,2,3]
this should give us the result [7, 14, 21] (and, in fact, if we try this out in ghci, this is exactly the result that we get).
Now sure we could have written a function that took a number and multiplied it by seven and then passed that function to map but, for a one-off application, sometimes it’s more straightforward to implement it directly like this. And, yes, this example is trivial but it highlights the capabilities that come from Haskell’s partial execution feature.
I ran out of time last night and I don’t think I really finished addressing the other important point of the foldl via foldr implementation (Haskell: foldl via foldr). So I thought I might take just a minute and try to get this point down before I forget…
The thing is that the final expansion of the expression:
forces the evaluation of the left-most term first – even though precedence would ordinarily force the right-most term to be evaluate first.
Think of it this way, ordinarily, the (id) term would evaluate first since it is the innermost term. But id is a function that requires a parameter to evaluate so it must wait until other terms are evaluated. It simply remains part of the expression as a function pointer to be evaluated later.
Next, we expand step 3 – remembering that step x g a is to be replaced by g (f a x):
In each of these expansions, I’m using a question mark as a placeholder for a parameter to a curried function. The re-ordering of the parameters in the step function actually obscures what’s going on but I think it’s about to be made clear anyway.
This final expanded expression now evaluates left to right with each question mark being filled in by the expression to the right. The id operator simply returns the value of the expression that follows. The expression that follows returns the sum of a yet-to-be determined value and 3. This yet to be determined value is simply the following expression: ((+) ? 2) but this expression is another curried function whose missing parameter is ((+) ? 1). But this final expression’s missing parameter is visible at the end of the line: 0.
Inserting this last parameter gives the preceding expression as ((+) 0 1) which gives the value 1. This, in turn, allows us to complete the expression that preceded it, giving us ((+) 1 2) which results in 3. And, finally, this allows us to complete the first expression ((+) ? 3) as ((+) 3 3), giving us the result 6.
So, following this logic, the curried function and the missing parameters results in a left-to right evaluation of our original list so that, even though foldr (+) [1,2,3] would ordinarily evaluate to (1 + (2 + (3 + 0))), we instead get id (((0 + 1) + 2) + 3)
Do we care? Well, arguably, this is simply a trumped up example and should probably never be attempted in real life (for both readability and performance reasons), the exercise of understanding it helps to drive home the point about how Haskell’s partial function evaluation works.
Spent some time this afternoon reading through Real World Haskell this afternoon exploring the topic of strict evaluation versus non-strict evaluation and came across an example of foldl implemented using foldr. After a mind-bending half-hour or so, I was able to piece together an idea of what is actually happening in this example so I’m noting it here to help me remember in the future.
The code in question is:
myFoldl :: (a -> b -> a) -> a -> [b] -> a
myFoldl f z xs = foldr step id xs z
where step x g a = g (f a x)
I’m attempting the function expansion in phases based on the following invocation:
myFoldl (+) 0 [1, 2, 3]
First, I’m ignoring the step function and simply expanding for each list member:
foldr (step) id (1:2:3:[]) 0
step 1 (foldr (step) id (2:3:[])) 0
step 1 (step 2 (foldr (step) id (3:[]))) 0
step 1 (step 2 (step 3 (foldr (step) id ([])))) 0
step 1 (step 2 (step 3 ( id ))) 0
Note carefully that the first line is a simply foldr invocation but there are too many parameters – there is an extra 0 at the end. This is carried through the entire expansion.
Now, I’ll expand the internal step method. This is tricky because it is a partial function and it seems to re-order the entire expression. As a reminder, the signature for this method is:
step x g a = g ((+) a x)
As I pointed out earlier, this pretty much rewrites the expansion above. To make it easier to follow, I’ll expand the outermost invocation of the step method first (see the block that follows the next paragraph – The line I’m going to expand appears first). The x parameter of the step method takes the value 1, the g parameter takes the value (step 2 (step 3 (id))).
Now, initially, it might appear that the a parameter does not have a value but as I hinted earlier, this is a trick of Haskell because the step function has been “curried” by the foldr invocation. In other words, this method has been partially invoked, resulting in a method that is awaiting its final parameter – a parameter that arrives by means of the extra 0 parameter supplied after the foldr.
The (step 2 (step 3 (id))) clause has been moved to the front as parameter g. Next, the f parameter passed into the outermost myFoldl function makes its return in the (f a x) clause of the step function body. In our example, f is simply the plus operator. Now that is followed by the step function’s a parameter then its x parameter. In our example, this simply evaluates to (a + x) (though in the odd, but perfectly legal equivalent expression ((+) a x) – yielding ((+) 0 1) which evaluates to 1).
While it would be perfectly valid to repeat this step and then compute the result after, I find it a little bit more intuitive to evaluate the expression now and then expand the next level for each invocation of step:
So, you can see (at least I hope you can see) that the myFoldl function yields the same result as foldl would but in a very backhanded way – which teaches us a little bit more about Haskell under the covers…






 in about 3.5 seconds (and another six seconds to display it) while the Haskell implementation computes and displays
in about 3.5 seconds (and another six seconds to display it) while the Haskell implementation computes and displays  in eight minutes while the Haskell implementation computes the same value and writes it to /dev/null in only two seconds.
in eight minutes while the Haskell implementation computes the same value and writes it to /dev/null in only two seconds. begins displaying in about 10 seconds and seems to pause every three seconds or so, sometimes for a barely noticeable fraction of a second and sometimes for ten or twenty seconds.
begins displaying in about 10 seconds and seems to pause every three seconds or so, sometimes for a barely noticeable fraction of a second and sometimes for ten or twenty seconds. (for the 64-bit version) until it finds the largest value that is less than the number to be converted. It then divides the number by this result to yield a List of two Integer values: the quotient and the remainder. This process is repeated until it has a List of Integers, each of which is less than
(for the 64-bit version) until it finds the largest value that is less than the number to be converted. It then divides the number by this result to yield a List of two Integer values: the quotient and the remainder. This process is repeated until it has a List of Integers, each of which is less than  . Each time such a number is divided, the algorithm must divide every digit. The traditional algorithm divides the entire number over and over again by 10, which reduces it by one order of magnitude each time. The highest order digit need only be divided about 18 or 19 times but the next to the highest digit is divided between 36 and 38 times (really, a little more than this, but let’s not split hairs). As we expand the series, we find that the sum of operations is roughly
. Each time such a number is divided, the algorithm must divide every digit. The traditional algorithm divides the entire number over and over again by 10, which reduces it by one order of magnitude each time. The highest order digit need only be divided about 18 or 19 times but the next to the highest digit is divided between 36 and 38 times (really, a little more than this, but let’s not split hairs). As we expand the series, we find that the sum of operations is roughly  where n is the number of 64-big “digits”. In computer science terms, I believe this equates to
where n is the number of 64-big “digits”. In computer science terms, I believe this equates to 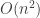 time.
time. . The next step is the repeated division to reduce the number into a list of base
. The next step is the repeated division to reduce the number into a list of base  . The final step is to divide each of the resulting “digits” into base 10 digits – the number of operations for this step grows at a rate of roughly
. The final step is to divide each of the resulting “digits” into base 10 digits – the number of operations for this step grows at a rate of roughly  .
. . This reduces to simply
. This reduces to simply  – showing that the Haskell algorithm runs in linear time. While its complexity may mean that it runs slower for smaller numbers (though I don’t think this is the case) it will rapidly outpace the performance of the typical algorithm, which runs in quadratic time, for any reasonably large Integer value.
– showing that the Haskell algorithm runs in linear time. While its complexity may mean that it runs slower for smaller numbers (though I don’t think this is the case) it will rapidly outpace the performance of the typical algorithm, which runs in quadratic time, for any reasonably large Integer value. , coming in at only 3.6 seconds compared to 6.3 seconds for Erlang’s native conversion.
, coming in at only 3.6 seconds compared to 6.3 seconds for Erlang’s native conversion. operations (where
operations (where  is the number of 64-bit integers in our number) – this step is irreducible. But we have sort of a shortcut here because we really only need to know the magnitude of the number we’re going to display at this point, not its precise value. This means that most of the time we need only resolve the most significant 64-bit digit (and to know the order of that digit) of it in order for this comparison to work.
is the number of 64-bit integers in our number) – this step is irreducible. But we have sort of a shortcut here because we really only need to know the magnitude of the number we’re going to display at this point, not its precise value. This means that most of the time we need only resolve the most significant 64-bit digit (and to know the order of that digit) of it in order for this comparison to work. operations. Not only is this less than the original
operations. Not only is this less than the original  it is less even than the
it is less even than the 








 where
where  and
and  so it was easy enough to implement. Haskell has built-in support for arbitrary precision integer math so my first implementation could calculate essentially any Fibonacci number that I had the patience to wait for. The problem was that this algorithm was expensive so, as I experimented with computing higher and higher ordered Fibonacci numbers, it quickly came to be like watching paint dry.
so it was easy enough to implement. Haskell has built-in support for arbitrary precision integer math so my first implementation could calculate essentially any Fibonacci number that I had the patience to wait for. The problem was that this algorithm was expensive so, as I experimented with computing higher and higher ordered Fibonacci numbers, it quickly came to be like watching paint dry. was 144. Now that’s a pretty odd coincidence (since
was 144. Now that’s a pretty odd coincidence (since  is also
is also  ) and while it was obvious that there was no such relationship for any other Fibonacci number, it made me curious so I started doodling with squares of Fibonacci numbers. It wasn’t long before I stumbled across the fact that
) and while it was obvious that there was no such relationship for any other Fibonacci number, it made me curious so I started doodling with squares of Fibonacci numbers. It wasn’t long before I stumbled across the fact that  . A little more mucking about revealed that this particular pattern (
. A little more mucking about revealed that this particular pattern ( ) persisted for every pair Fibonacci numbers that I cared to try. A quick look at Wikipedia (see
) persisted for every pair Fibonacci numbers that I cared to try. A quick look at Wikipedia (see 
 . This formula provided a way to rapidly calculate the series
. This formula provided a way to rapidly calculate the series  for
for  and to compute the ‘sum’ of any combination of these values to generate any arbitrary Fibonacci number (i.e.
and to compute the ‘sum’ of any combination of these values to generate any arbitrary Fibonacci number (i.e.  ).
).