
Comparing the results of my Fibonacci calculator in Haskell to those in Erlang revealed a few things. First of all, there was a bug in my Haskell implementation! The corrected version is:
import Data.List (genericIndex)
import Data.Bits
import System.Environment (getArgs)
-- simple Haskell demo to compute an arbitrarily large Fibonacci number.
--
-- this program relies primarily on the principle that F(n+k) = F(n-1)*F(k)+F(n)*F(k+1)
-- from which we find that F(2n) = F(n-1)*F(n) + F(n)*F(n+1) = F(n-1)*F(n) + F(n)*(F(n) + F(n-1))
-- Using the second equation, it is a simple matter to sequentially construct F(2^n) for any value n.
-- With this tool in hand, F(N) may be computed for any N by simply breaking N down into its constituent
-- 2^n components (e.g. N = 14 = 8 + 4 + 2 = 2^3 + 2^2 + 2^1) and to then use these results to guide
-- construction of the value we want by summing each of the F(2^n) using the F(n+k) identities described above
-- given two Fibonacci pairs representing F(n-1),F(n) and F(k-1),F(k), compute F(n+k-1), F(n+k)
fibSum :: (Integer, Integer) -> (Integer, Integer) -> (Integer, Integer)
fibSum (fnminus1, fn) (fkminus1, fk) =
(fnminus1*fkminus1 + fn*fk, fnminus1*fk+fn*(fkminus1+fk))
-- given an integer (representing the ordinal of the Fibonacci pair to be retrieved working value and a Fibonacci pair accumulator value,
-- compute return the sum of all Fibonacci values corresponding to the bits in N. For example, given a value of ten for N in F(N) -
-- bit values: False (2^0 = 1), True (2^1 = 2), False (2^2 = 4), True (2^3 = 8) - compute the sum of F(2 + 8)
fibGenerator :: Integer -> (Integer, Integer) -> (Integer, Integer) -> (Integer, Integer)
fibGenerator (n) tuple accumulator | (n == 0) = accumulator
| ((n .&. 1) == 1) = fibGenerator (shiftR n 1) (fibSum tuple tuple) (fibSum tuple accumulator)
| ((n .&. 1) == 0) = fibGenerator (shiftR n 1) (fibSum tuple tuple) accumulator
-- given a positive integer value N, compute and return Fib(N)
fib :: Integer -> Integer
fib (n) | n 0 = snd ( fibGenerator (n - 1) (0, 1) (0, 1))
-- main :: reads our argument and computes then displays corresponding Fibonacci number
main = do
args
Second of all, there was a significant difference in the performance of the two implementations. Since one was an almost direct port of the other, it was unlikely that the cause was in the code so it must be something inherent in the languages.
Haskell uses something called “non-strict” evaluation, meaning essentially that results of expressions are evaluated when they are needed and expressions whose results are never needed are never evaluated. In contrast, Erlang uses strict evaluation, meaning that each expression – whether its result is used or not – is computed in its entirety and the value stored. Of course non-strict evaluation can make certain types of operations more efficient but this is unlikely to make a big difference in the actual performance of the two implementations because the computation of Fibonacci numbers is largely a cpu-bound operation with few, if any, steps that can be skipped.
How big a difference is there between the two? Well, on my test virtual machine, the Erlang implementation computes 

Obviously, the difference between the two has to do with optimizations in the Haskell Integer library that are not present in the Erlang Integer library. There is also the possibility that the fact that Haskell is compiled and Erlang runs in its own virtual machine but I doubt this makes much of a difference. It’s fair to point out that Erlang has a principally business computing background while Haskell appears to me to have lived a long life in academic circles before entering the commercial world. It wouldn’t be the least bit surprising to find that the Haskell Integer library has received a little more attention.
But something interesting begins to emerge as larger and larger values are tried. Once it gets started, Erlang displays results at a very steady (and very swift) pace – pretty much what you would expect. Haskell, on the other hand, begins to display results in bursts of digits with larger numbers. For example, 
While it’s possible that this has to do with memory management in Haskell, I don’t believe it is. After all, the resulting number has only about 20 million digits while the virtual machine has 2 GB allocated. There isn’t really that much memory to manage.
Looking closely at the cpu profile makes the memory management interpretation seem even less likely. A single processor core ascends to 100% as soon as the program is launched. After about ten seconds, this core drops to about 20% while a few other cores also rise to 30%. This roughly coincides with the time that the program begins to display its results. After a relatively quiet period of five seconds, the original core rises once again to 100% (as all other cores idle down) and remains there for about ten seconds – during most of which time the display halts. Finally, this core drops once again to about 20% and the output resumes. For the rest of the run time, the load is largely distributed across all four cores allocated to my test virtual machine.
Clearly, the program is still hard at work as it displays the result but the question is: what is it doing? As I suggested in my last post, I suspect that it is still computing the result. All the evidence so far would seem to support this idea – but there is a catch:
To display the resulting Fibonacci number, the program must first convert it to a string in base 10. The way this is typically done is through successive integer division: divide the number by 10 which yields a remainder between zero and nine representing the least significant digit and a quotient representing all remaining digits. This approach can be successively applied to generate the digits one at a time starting with the least significant and ending with the most significant.
But if Haskell used this algorithm, it’s non-strict evaluation would be neutralized and it would have to perform every single calculation before it could display even the first digit. We would expect to see the exact behavior that we see from Erlang – a long delay and then a rapid stream of digits whose speed was paced only by the write speed of the video card. To get to the bottom of this puzzle, we have to look at Haskell’s algorithm to convert an Integer into a base 10 string. The function that does this is appropriately named integerToString and begins on line 479 of Show.lhs. This algorithm takes a completely different approach from the one described above and delivers two improvements: it is more efficient and it works better with Haskell’s non-strict evaluation.
The algorithm Haskell uses employs a “divide and conquer” strategy to reduce the original Integer into a List of Integer values by first repeatedly squaring 
So, how is this faster? Well, first it helps to think of an Integer value as a list of 64-bit integers – essentially digits in base 

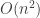
The Haskell algorithm involves first the repeated squaring to find the greatest power of 


So, based on the above, the total operations for presenting a number with the Haskell algorithm is 

To demonstrate this point for myself, I ported the Haskell algorithm to Erlang and gave it a try with my Fibonacci generator. Naturally, it had no impact on the rate at which the numbers were generated and it was hampered by the performance of the Integer library in Erlang but, nevertheless, it proved to be twice as fast at displaying the result of 
So this addresses how the Haskell algorithm is faster but what is it about this algorithm that makes it a better fit for non-strict evaluation? Well, as I pointed out earlier, the traditional base conversion algorithm would completely neutralize Haskell’s non-strict evaluation so it would be hard for it to be a worse fit. But let’s look at what steps Haskell must perform in order to find the first digit.
First, Haskell must perform all of the steps required to select a power of 

Next, Haskell must break down the number by successively reducing it into a quotient and remainder. But here, we have a another shortcut – we are only concerned with the quotient, which means we can just park the remainder for now (in fact, I’m relatively certain that we don’t even need to calculate the low-order half of our Fibonacci number at this point). So, instead of completing the full series of
Finally, we only need to convert the top-most base
Taken together, presentation of the first digit requires only 

 where
where  and
and  so it was easy enough to implement. Haskell has built-in support for arbitrary precision integer math so my first implementation could calculate essentially any Fibonacci number that I had the patience to wait for. The problem was that this algorithm was expensive so, as I experimented with computing higher and higher ordered Fibonacci numbers, it quickly came to be like watching paint dry.
so it was easy enough to implement. Haskell has built-in support for arbitrary precision integer math so my first implementation could calculate essentially any Fibonacci number that I had the patience to wait for. The problem was that this algorithm was expensive so, as I experimented with computing higher and higher ordered Fibonacci numbers, it quickly came to be like watching paint dry. was 144. Now that’s a pretty odd coincidence (since
was 144. Now that’s a pretty odd coincidence (since  is also
is also  ) and while it was obvious that there was no such relationship for any other Fibonacci number, it made me curious so I started doodling with squares of Fibonacci numbers. It wasn’t long before I stumbled across the fact that
) and while it was obvious that there was no such relationship for any other Fibonacci number, it made me curious so I started doodling with squares of Fibonacci numbers. It wasn’t long before I stumbled across the fact that  . A little more mucking about revealed that this particular pattern (
. A little more mucking about revealed that this particular pattern ( ) persisted for every pair Fibonacci numbers that I cared to try. A quick look at Wikipedia (see
) persisted for every pair Fibonacci numbers that I cared to try. A quick look at Wikipedia (see 
 . This formula provided a way to rapidly calculate the series
. This formula provided a way to rapidly calculate the series  for
for  and to compute the ‘sum’ of any combination of these values to generate any arbitrary Fibonacci number (i.e.
and to compute the ‘sum’ of any combination of these values to generate any arbitrary Fibonacci number (i.e.  ).
).